
微服务
springcloud-RestTemplate
说明
微服务中分消费者(调用服务的)和提供者(被调用的服务),角色是相对的,一个服务既可以是提供者也可以是消费者
要注意版本的问题
微服务项目中,当一个模块需要向另一个模块数据和操作时,微服务远程调用
spring中提供了一个工具restTemplate1
2
3
4
5
6<!--spring cloud-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.3</version>
</dependency>配置
在配置类中(启动类也属于配置类)注册bean对象1
2
3
4
public RestTemplate restTemplate() {
return new RestTemplate();
}使用
在需要发送请求的服务中,使用RestTemplate对象发送请求即可,列如:
如下场景中,购物车服务cart-service需要向商品服务item-service查询商品信息,此时需要远程调用商品服务,使用RestTemplate:2.1~2.31
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
public class CartServiceImpl extends ServiceImpl<CartMapper, Cart> implements ICartService {
// 1.注入restTemplate
private RestTemplate restTemplate;
// 2.查询我的购物车列表
public List<CartVO> queryMyCarts() {
// 1.查询我的购物车列表
List<Cart> carts = lambdaQuery().eq(Cart::getUserId, 1L/*TODO UserContext.getUser()*/).list();
if (CollUtils.isEmpty(carts)) {
return CollUtils.emptyList();
}
// 2.转换VO
List<CartVO> vos = BeanUtils.copyList(carts, CartVO.class);
// 3.处理VO中的商品信息
handleCartItems(vos);
// 4.返回
return vos;
}
// 3.远程调用商品服务
private void handleCartItems(List<CartVO> vos) {
//TODO 1.获取商品id
Set<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet());
/* // 2.查询商品 ,为单体项目时,直接调用商品查询即可,现在拆分为微服务模块
List<ItemDTO> items = itemService.queryItemByIds(itemIds);
if (CollUtils.isEmpty(items)) {
return;
}*/
//2.查询商品
//2.1 发送商品管理服务(item-service)远端请求
ResponseEntity<List<ItemDTO>> response = restTemplate.exchange(
"http://localhost:8081/items?ids={ids}", // url 根据商品id查询商品列表
HttpMethod.GET, // 请求方式
null, // 请求实体
new ParameterizedTypeReference<List<ItemDTO>>() {}, // 返回值类型
Map.of("ids", CollUtil.join(itemIds, ","))
);
//2.2 解析响应,判断是否成功
if (!response.getStatusCode().is2xxSuccessful()) {
// 失败
return;
}
//2.3 解析响应,获取数据
List<ItemDTO> items = response.getBody();
if (CollUtils.isEmpty(items)) {
return;
}
// 3.转为 id 到 item的map
Map<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity()));
// 4.写入vo
for (CartVO v : vos) {
ItemDTO item = itemMap.get(v.getItemId());
if (item == null) {
continue;
}
v.setNewPrice(item.getPrice());
v.setStatus(item.getStatus());
v.setStock(item.getStock());
}
}
}总结
在这个过程中,item-service提供了查询接口,cart-service利用Http请求调用该接口。因此item-service可以称为服务的提供者,而cart-service则称为服务的消费者或服务调用者
Eureka
eureka的作用
消费者该如何获取服务提供者具体信息?
- 服务提供者启动时向eureka注册自己的信息
- eureka保存这些信息
- 消费者根据服务名称向eureka拉取提供者信息
如果有多个服务提供者,消费者该如何选择?
- 服务消费者利用负载均衡算法,从服务列表中挑选一个
消费者如何感知服务提供者健康状态?
- 服务提供者会每隔30秒向EurekaServer发送心跳请求,报告健康状态
- eureka会更新记录服务列表信息,心跳不正常会被剔除
- 消费者就可以拉取到最新的信息
搭建EurekaServer
eureka也是个微服务,eureka在启动的时候也会把自己注册到eureka上
1.创建maven项目,引入spring-cloud-starter-netflix-eureka-server的依赖1
2
3
4
5<dependency>
<!--eureka服务端依赖-->
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
2.编写启动类,添加@EnableEurekaServer注解1
2
3
4
5
6
7
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}
3.添加application.yml文件,编写下面的配置:1
2
3
4
5
6
7
8
9
10server:
port: 10086 #服务端口
spring:
application:
name: eurekaserver #服务名称
eureka:
client:
service-url: #eurek的地址信息
defaultZone: http://127.0.0.1:10086/eureka #注册中心地址
服务注册:注册user-service
1.在user-service项目下引入spring-cloud-starter-netflix-eureka-client的依赖1
2
3
4
5<dependency>
<!--eureka客户端端依赖-->
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
2.在application.yml文件,编写下面的配置1
2
3
4
5
6
7
8
9spring:
application:
name: userservice #服务名称
eureka:
client:
service-url: #eurek的地址信息
defaultZone: http://127.0.0.1:10086/eureka #注册中心地址
我们还可以将一个服务多次启动,来模拟多实例部署,但为了避免端口冲突,需要修改端口设置:
- 在idea下方Services(服务)窗口中
- 右键目标服务,选择CopConfiguration(复制配置)
- 旧版idea,就在Environment项下的VM options里输入:
-Dserver.port=端口号 - 新版idea中,选择修改配置,在修改选项中勾选允许多个实例即可,按alter+p 覆盖配置属性 server.port 8082
前面发送http请求时,远程调用的url地址是写死了的,现在就可以用eureka完解决该问题
服务发现(拉取)
前面orderService中,因为需要获取完整的订单的信息,所以通过resrtemplate发送http请求来获取对应的user信息
服务拉取是基于服务名称获取服务列表,然后在对服务列表做负载均衡
1.修改OrderService的代码,修改访问的url路径,用服务名代替ip、端口:String url="http://userservice/user/"+order.getUserId()
- 在order-service项目的启动类OrderApplication中的RestTemplate添加负载均衡注解:
1
2
3
4
5
public RestTemplate restTemplate() {
return new RestTemplate();
}
oderservice需要调用userservice,而userservice有多个实例时,可以通过定义IRule实现来修改负载均衡规则,有两种方式
1.代码方式:在消费者的启动类中,定义一个新的IRule(作用于全体)1
2
3
4
public IRule randomRule() {
return new RandomRule();
}
2.配置文件方式:在消费者的applicatiuon.yml文件中,添加新的配置也可以修改规则(针对某个微服务):1
2
3
4userservice:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #负载均衡规则
饥饿加载
ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,可以通过下面的配置开启饥饿加载1
2
3
4
5ribbon:
eager-load:
enabled: true #开启饥饿加载
clients:
- userservice #指定饥饿加载的服务
Nacos
官网:nacos.io
启动:在bin目录进入cmd,执行startup.cmd -m standalone
浏览器输入运行成功的 Console的值即可看到nacos控制台界面
默认为8848端口:localhost:88848/nacos 可以在conf下的application.properties下修改
服务注册到Nacos
1.在cloud-demo父工程中添加spring-cloud-alilbaba的管理依赖:1
2
3
4
5
6
7
8<!-- nacos的管理依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
2.注释之前的服务中的eureka依赖
3.添加Nacos的客户端依赖1
2
3
4
5<!-- nacos客户端依赖包-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
4.修改application.yml文件(并注释掉eureka的配置)1
2
3
4
5spring:
cloud:
nacos:
discovery:
server-addr: localhost:8848 #nacos服务地址
Nacos服务分级模型
- Nacos服务分级存储模型
① 一级是服务,例如userservice
②二级是集群,例如杭州或上海
③三级是实例,例如杭州机房的某台部署了userservice的服务器 - 如何设置实例的集群属性
① 修改application.yml文件,添加spring.cloud.nacos.discovery.cluster-name属性即可,如:1
2
3
4
5
6spring:
cloud:
nacos:
discovery:
server-addr: localhost:8848 #nacos服务地址
cluster-name: HN #集群名称 HN代指湖南
Nacos负载均衡
使服务优先访问集群内的服务
举例现在基于上面的配置,现在有一个order服务,,一个实例,属于集群HN,一个user服务,3个实例,2个属于HN集群,1个属于HZ集群。现在用order服务向user服务发送多次请求,发现三个实例均被调用到(能观察到都有日志输出)
现在对order服务中application.yml,添加如下负载均衡策略1
2
3userservice: #要做配置的微服务名称
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule #负载均衡规则
重启order服务,再次发送请求,可以看到,只有属于同一个集群的两个user服务响应了。即:优先选择本地集群,再在本地集群的多个服务当中随机访问(注意:不是轮询访问)。如果本地服务没有,或者本地服务挂了,才会跨集群访问(注意:不是跨集群就不能访问了)
总结Nacos负载均衡策略
1.优先选择同集群服务实例列表
2.本地集群找不到提供者,才去其它集群寻找,并且会报警告
3.确定了可用实例列表后,再采用随机负载均衡挑选实例
根据权重负载均衡
1.在nacos控制台可以点击实例后的编辑按钮即可修改权重
2.权重值为0~1,将权重配置为0.1即可大大降低被访问的频率
3.如果权重调成0,将不会被访问到
环境隔离-namespace(命名空间)
1.在Nacos控制台可以创建namespace,用来隔离不同的环境
- 在左侧菜单栏点击命名空间,再点击新建命名空间
- 填写命名空间名和描述信息
2.在application.yml配置文件中添加命名空间,值为命名空间id1
2
3
4
5spring:
cloud:
nacos:
discovery:
namespace: #dev环境
每个namespace都有唯一id,不同namespace下的服务不可见
nacos中的实例默认为临时实例,当实例状态为不健康时会直接在服务列表里干掉,设置为非临时实例,nacos则会每隔一段时间会查询服务的健康状态。
设置如下配置即可将配置该为非临时实例。1
2
3
4
5spring:
cloud:
nacos:
discovery:
ephemeral: false #是否是临时实例
Nacos于Eureka对比
Nacos与eureka的共同点
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
Nacos与Eureka的区别
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时
实例时,采用CP模式;Eureka采用AP方式
Nacos配置管理
配置更改热更新
将配置交给nacos管理
在nacos的配置管理的配置列表中点击创建配置
- Data ID: 唯一,服务名称-profile(运行环境).yaml,如、shared-test.yaml
- Group: 一般默认即可
- 描述:写配置文件作用,如、userservice的开发配置文件
- 配置格式: yaml
- 配置内容: 一般写那些需要更改的配置,
- 再点击发布即可
配置如下信息便于下面验证:1
2pattern:
dateformat: yyyy-MM-dd HH:mm:ss
让微服务读取nacos中配置文件
配置获取的步骤如下:
项目启动->读取nacos中配置文件->读取本地配置文件application.yml->创建spring容器->加载bean
1.引入Nacos的配置管理客户端依赖:1
2
3
4
5
6
7
8
9
10<!--nacos的配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--读取bootstrap.yml文件-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
2.在userservice中的resource目录添加一个bootstrap.yml文件,这个文件是引导文件,优先级高于application.yml1
2
3
4
5
6
7
8
9
10
11
12
13spring:
application:
name: user-service # 服务名称
profiles:
active: dev #环境
cloud:
nacos:
server-addr: 192.168.40.101:8848 # nacos 地址
config:
file-extension: yaml # 文件后缀名
shared-configs: #共享配置
- dataId: shared-jdbc.yaml #共享mybatis配置
- dataId: shared-test.yaml #服务 配置
在user服务里读取配置来验证是否成功1
2
3
4
5
6
7
private String dateformat;
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));
}
多环境配置共享
微服务会从nacos中读取配置文件:
1.[服务名]-[spring.profile.active].yaml,环境配置
2.[服务名].yaml,默认配置,多环境共享
我们需要了解配置文件的优先级:
[服务名]-[环境].yaml>[服务名].yaml>本地配置
如:userservice-dev.yaml>userservice.yaml>本地的application.yaml
所以我们可以在nacos中新建一个服务名.yaml的配置文件,在里面填写我们的多环境共享配置。
统一服务在不同环境下能访问到公共环境配置,但如果当配置属性相同时,按优先级来
配置热更新
有很多的业务相关参数,将来可能会根据实际情况临时调整。例如购物车业务,购物车数量有一个上限,默认是10,对应代码如下:1
2
3
4
5
6
7
8//检查购物车是否已满
private void checkCartsFull(Long userId) {
// 查询当前用户购物车数量
int count = lambdaQuery().eq(Cart::getUserId, userId).count();
if (count >= 10) {
throw new BizIllegalException(StrUtil.format("用户购物车课程不能超过{}", 10));
}
}
现在这里购物车是写死的固定值,我们应该将其配置在配置文件中,方便后期修改。解决办法如下:
添加配置到nacos中:
在nacos中新建一个配置文件,将购物车上限数量添加到配置当中- 在naocs管理界面:配置管理->配置列表->右上角+新建配置
- DataID:
cart-service,这里没有写dev或local等后缀,表示所有环境都适用 - 配置格式:
YAML - 配置内容:
1
2
3hm:
cart:
maxAmount: 2 #购物车商品上限 - 点击发布即可
在微服务中读取配置,实现配置热更新
在cart-service中新建一个属性读取类1
2
3
4
5
6
public class CartProperties {
private Integer maxAmount;
}然后在业务中使用该属性类
1
2
3
4
5
6
7
8
9
10
private CartProperties cartProperties;
//检查购物车是否已满
private void checkCartsFull(Long userId) {
int count = lambdaQuery().eq(Cart::getUserId, userId).count();
if (count >= cartProperties.getMaxAmount()) {
throw new BizIllegalException(StrUtil.format("用户购物车课程不能超过{}", cartProperties.getMaxAmount()));
}
}测试:
重启服务,选择商品加入购物车,发现数量已经最大为2
修改nacos中的配置,将maxAmount的值改为3,点击发布,发现数量已经最大为3
至此实现了配置热更新
Nacos简化理解
在微服务远程调用的过程中,包括两个角色:
- 服务提供者:提供接口供其它微服务访问,比如item-service
- 服务消费者:调用其它微服务提供的接口,比如cart-service
在大型微服务项目中,服务提供者的数量会非常多,为了管理这些服务就引入了注册中心的概念。注册中心、服务提供者、服务消费者三者间关系如下:
目前开源的注册中心框架有很多,国内比较常见的有:
- Eureka:Netflix公司出品,目前被集成在SpringCloud当中,一般用于Java应用
- Nacos:Alibaba公司出品,目前被集成在SpringCloudAlibaba中,一般用于Java应用
- Consul:HashiCorp公司出品,目前集成在SpringCloud中,不限制微服务语言
nacos官网如下
如果在虚拟机上安装并启动好nacos,访问 http://192.168.40.101:8848/nacos/ ,注意将192.168.40.101替换为你自己的虚拟机IP地址。
服务注册
引入依赖
1
2
3
4
5
6<!--nacos 服务注册发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>2021.0.4.0</version>
</dependency>注册nacos
1
2
3
4
5
6spring:
application:
name: item-service # 服务名称这里为商品管理
cloud:
nacos:
server-addr: 192.168.40.101:8848 # nacos地址访问nacos控制台,在nacos控制台的服务管理/服务列表中可以看到
服务发现
服务的消费者要去nacos订阅服务,这个过程就是服务发现,步骤如下:
- 引入依赖
- 配置Nacos地址
- 发现并调用服务
服务发现除了要引入nacos依赖以外,由于还需要负载均衡,因此要引入SpringCloud提供的LoadBalancer依赖。
1
2
3
4
5
6<!--nacos 服务注册发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>2021.0.4.0</version>
</dependency>1
2
3
4
5
6spring:
application:
name: cart-service #消费者,购物车服务
cloud:
nacos:
server-addr: 192.168.40.101:8848 # nacos地址调用服务
上面的RestTemplate中,发送请求的地址为硬编码,而我们现在使用了nacos,就可以从naocs中获取服务地址,从而实现负载均衡。
步骤:根据服务名获取实例列表,设置负载均衡策略,获取实例,再发送请求。
服务发现需要用到一个工具,DiscoveryClient,SpringCloud已经帮我们自动装配,我们可以直接注入使用:
见下方示例代码36~42行1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
public class CartServiceImpl extends ServiceImpl<CartMapper, Cart> implements ICartService {
// 1.注入restTemplate
private RestTemplate restTemplate;
// 注入DiscoveryClient
private DiscoveryClient discoveryClient;
// 2.查询我的购物车列表
public List<CartVO> queryMyCarts() {
// 1.查询我的购物车列表
List<Cart> carts = lambdaQuery().eq(Cart::getUserId, 1L/*TODO UserContext.getUser()*/).list();
if (CollUtils.isEmpty(carts)) {
return CollUtils.emptyList();
}
// 2.转换VO
List<CartVO> vos = BeanUtils.copyList(carts, CartVO.class);
// 3.处理VO中的商品信息
handleCartItems(vos);
// 4.返回
return vos;
}
// 3.远程调用商品服务
private void handleCartItems(List<CartVO> vos) {
//TODO 1.获取商品id
Set<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet())
//根据服务名称发现实例列表
List<ServiceInstance> instances = discoveryClient.getInstances("item-service");
if(CollUtil.isEmpty(instances)){
return;
}
//设置负均衡,随机获取一个实例
ServiceInstance serviceInstance = instances.get(RandomUtil.randomInt(instances.size()));
//2.查询商品
//2.1 发送商品管理服务(item-service)远端请求
ResponseEntity<List<ItemDTO>> response = restTemplate.exchange(
serviceInstance.getUri()+"/items?ids={ids}", // url 根据商品id查询商品列表
HttpMethod.GET, // 请求方式
null, // 请求实体
new ParameterizedTypeReference<List<ItemDTO>>() {}, // 返回值类型
Map.of("ids", CollUtil.join(itemIds, ","))
);
//2.2 解析响应,判断是否成功
if (!response.getStatusCode().is2xxSuccessful()) {
// 失败
return;
}
//2.3 解析响应,获取数据
List<ItemDTO> items = response.getBody();
if (CollUtils.isEmpty(items)) {
return;
}
// 3.转为 id 到 item的map
Map<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity()));
// 4.写入vo
for (CartVO v : vos) {
ItemDTO item = itemMap.get(v.getItemId());
if (item == null) {
continue;
}
v.setNewPrice(item.getPrice());
v.setStatus(item.getStatus());
v.setStock(item.getStock());
}
}
}
http客户端Feign-OpenFeign
在上面,我们利用Nacos实现了服务的治理,利用RestTemplate实现了服务的远程调用。但是远程调用的代码太复杂了
而且这种调用方式,与原本的本地方法调用差异太大,编程时的体验也不统一,一会儿远程调用,一会儿本地调用。
因此,我们必须想办法改变远程调用的开发模式,让远程调用像本地方法调用一样简单。而这就要用到OpenFeign组件了。
其实远程调用的关键点就在于四个:
- 请求方式
- 请求路径
- 请求参数
- 返回值类型
所以,OpenFeign就利用SpringMVC的相关注解来声明上述4个参数,然后基于动态代理帮我们生成远程调用的代码,而无需我们手动再编写,非常方便。
定义和使用Feign客户端
引入依赖
1
2
3
4
5
6
7
8
9
10
11
12<!--openFeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>2021.0.4.0</version>
</dependency>
<!--负载均衡器-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
<version>3.1.3</version>
</dependency>在cart-service的启动类上添加注解开启Feign的功能
@EnableFeignClients// 开启feign
编写Feign客户端:
主要是基于SpringMVC的注解来声明远程调用的信息,比如:- 服务名称:item-service
- 请求方式:GET
- 请求路径:/items
- 请求参数:Collection
ids - 返回值类型:List
1
2
3
4
5
6// 调用的服务名
public interface ItemClient {
// 调用的服务地址
List<ItemDTO> queryItemByIds( Collection<Long> ids);
}
对比下面两个
不再需要RestTemplate和DiscoveryClient了,原本的复杂的代码也删掉了,只需要调用Feign客户端即可。并且代码更简洁,更易读。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
public class CartServiceImpl extends ServiceImpl<CartMapper, Cart> implements ICartService {
private ItemClient itemClient;
public List<CartVO> queryMyCarts() {
// 1.查询我的购物车列表
List<Cart> carts = lambdaQuery().eq(Cart::getUserId, 1L/*TODO UserContext.getUser()*/).list();
if (CollUtils.isEmpty(carts)) {
return CollUtils.emptyList();
}
// 2.转换VO
List<CartVO> vos = BeanUtils.copyList(carts, CartVO.class);
// 3.处理VO中的商品信息
handleCartItems(vos);
// 4.返回
return vos;
}
private void handleCartItems(List<CartVO> vos) {
//TODO 1.获取商品id
Set<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet());
// 2.查询商品
List<ItemDTO> items = itemClient.queryItemByIds(itemIds);
if(CollUtil.isEmpty(items)){
return;
}
// 3.转为 id 到 item的map
Map<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity()));
// 4.写入vo
for (CartVO v : vos) {
ItemDTO item = itemMap.get(v.getItemId());
if (item == null) {
continue;
}
v.setNewPrice(item.getPrice());
v.setStatus(item.getStatus());
v.setStock(item.getStock());
}
}
}
可以看到接口和我们在cart-service中使用FeignClient声明的接口是一致的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class ItemController {
private final IItemService itemService;
public List<ItemDTO> queryItemByIds( List<Long> ids){
return itemService.queryItemByIds(ids);
}
}
自定义Feign的配置
Feign运行自定义配置来覆盖默认配置,可以修改的配置如下:
| 类型 | 作用 | 说明 |
|---|---|---|
| feign.Logger.Level | 修改日志级别 | 包含四种不同的级别:NONE、BASIC、HEADERS、FULL |
| feign.codec.Decoder | 响应结果的解析器 | http远程调用的结果做解析,例如解析json字符串为java对象 |
| feign.codec.Encoder | 请求参数编码 | 将请求参数编码,便于通过http请求发送 |
| feign.Contract | 支持的注解格式 | 默认是SpringMVC的注解 |
| feign.Retryer | 失败重试机制 | 请求失败的重试机制,默认是没有,不过会使用Ribbon的重试 |
一般我们需要配置的就是日志级别。配置Feign日志有两种方式:
1 | feign: |
首先声明一个Bean:1
2
3
4
5
6public class DefaultFeignConfiguration {
public Logger.Level feignLoggerLevel() {
return Logger.Level.BASIC;// 日志级别
}
}
该配置类暂时不会生效,使它生效的话
如果要全局配置,则把它放到@EnableFeignClients注解里
如:@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration.class)// 开启feign
如果要局部配置,则把它放到@FeignClient注解里
如:@FeignClient(value = "userservice",configuration = DefaultFeignConfiguration.class)// 调用userservice服务
那么该日志就只针对userservice服务
Feign的性能优化-连接池和日志
优化feign的性能主要包括:
1.默认底层实现的每次访问都需要去创建一个新的请求,使用连接池代替默认的URLConnection,依赖于其他框架,主要有下面三种- HttpURLConnection: 默认实现,不支持连接池
- Apache HttpClient: 支持连接池
- OKHttp: 支持连接池
2.OpenFeign只会在FeignClient所在包的日志级别为DEBUG时,才会输出日志。而且其日志级别有4级:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Feign默认的日志级别就是NONE,所以默认我们看不到请求日志。
feign性能优化-连接池配置
- 引入
okhttp依赖1
2
3
4
5<!--OK http 的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-okhttp</artifactId>
</dependency> - 开启连接池
1
2
3feign:
okhttp:
enabled: true # 开启OKHttp功能
- 引入
feign性能优化-日志级别配置
- 定义一个Feign配置类,定义Feign的日志级别:
1
2
3
4
5
6
7
8
9import feign.Logger;
import org.springframework.context.annotation.Bean;
public class DefaultFeignConfig {
public Logger.Level logLevel() {
return Logger.Level.FULL;
}
} - 接下来,要让日志级别生效,还需要配置这个类。有两种方式:
- 局部生效:在某个FeignClient中配置,只对当前FeignClient生效
1
- 全局生效:在
@EnableFeignClients注解中配置,对所有FeignClient生效1
- 局部生效:在某个FeignClient中配置,只对当前FeignClient生效
- 定义一个Feign配置类,定义Feign的日志级别:
OpenFeign传递登录用户信息
情景
前端发起的请求都会经过网关再到微服务,如果在网关中编写过过滤器和拦截器功能,微服务可以轻松获取登录用户信息。
但有些业务是比较复杂的,请求到达微服务后还需要调用其它多个微服务。
由于微服务获取用户信息是通过拦截器在请求头中读取,因此要想实现微服务之间的用户信息传递,就必须在微服务发起调用时把用户信息存入请求头。解决方案
微服务之间调用是基于OpenFeign来实现的,并不是我们自己发送的请求。我们如何才能让每一个由OpenFeign发起的请求自动携带登录用户信息呢?
这里要借助Feign中提供的一个拦截器接口:feign.RequestInterceptor1
2
3
4
5
6
7
8public interface RequestInterceptor {
/**
* Called for every request.
* Add data using methods on the supplied {@link RequestTemplate}.
*/
void apply(RequestTemplate template);
}只需要实现这个接口,然后实现apply方法,利用RequestTemplate类来添加请求头,将用户信息保存到请求头中。这样以来,每次OpenFeign发起请求的时候都会调用该方法,传递用户信息。
实现
由于FeignClient全部都是在hm-api模块,因此我们在hm-api模块的com.hmall.api.config.DefaultFeignConfig中编写这个拦截器:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class DefaultFeignConfig {
// 配置拦截器
public RequestInterceptor requestInterceptor() {
return new RequestInterceptor() {
public void apply(RequestTemplate requestTemplate) {
Long userID = UserContext.getUser();
if(userID!=null){
requestTemplate.header("userinfo", userID.toString());
}
}
};
}
}注意,要让其生效,需要在使用FeignClient的微服务启动类上加
@EnableFeignClients注解中配置,对所有FeignClient生效。1
OpenFeign整合Sentinel
当我们使用Sentinel对线程进行了隔离,通过限流来降低服务器压力,尽量减少因并发流量引起的服务故障的概率,但并不能完全避免服务故障。
一旦某个服务出现故障,我们必须隔离对这个服务的调用,避免发生雪崩。
比如,查询购物车的时候需要查询商品,为了避免因商品服务出现故障导致购物车服务级联失败,我们可以把购物车业务中查询商品的部分隔离起来,限制可用的线程资源:
这样,即便商品服务出现故障,最多导致查询购物车业务故障,并且可用的线程资源也被限定在一定范围,不会导致整个购物车服务崩溃。
这时就可以使用fallback机制来解决业务故障异常。
修改cart-service模块的application.yml文件,开启Feign的sentinel功能
1
2
3feign:
sentinel:
enabled: true # 开启feign对sentinel的支持在api调用模块中,创建一个类实现
FallbackFactory<>接口,并注册为bean1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class ItemClientFallbackFactory implements FallbackFactory<ItemClient>{
public ItemClient create(Throwable cause) {
return new ItemClient() {
public List<ItemDTO> queryItemByIds(Collection<Long> ids) {
log.error("查询购物车商品信息失败!",cause);
return CollUtils.emptyList();
}
public void deductStock(List<OrderDetailDTO> items) {
log.error("扣减库存数量失败!",cause);
throw new RuntimeException("扣减库存数量失败异常");
}
};
}
}在调用方,使用OpenFeign的fallback机制,指定fallback类,当调用失败时,会调用指定的fallback类。
1
2// 调用的服务名
public interface ItemClient {}
统一网关Gateway
网关功能有:身份认证和权限校验、服务路由、负载均衡、请求限流…
在SpringCloud中网关的实现包括两种:gateway 和 zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。
由于网关本身也是一个独立的微服务,因此也需要创建一个模块开发功能。
搭建网关服务
创建新的module,引入SpringCloudGateway的依赖和nacos的服务发现依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos discovery-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--负载均衡-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>创建启动类
1
2
3
4
5
6
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}创建
application.yml编辑路由配置以及nacos地址1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29server:
port: 8080 # 网关端口
spring:
application:
name: gateway # 服务名称 网关本身也是一个服务将注册进naocs
cloud:
nacos:
discovery:
server-addr: 192.168.40.101:8848 #配置Nacos地址
gateway:
routes: # 网关路由配置
- id: user # 路由规则id,自定义,唯一
uri: lb://user-service # 路由的目标地址,支持lb和http两种格式,lb代表负载均衡,会从注册中心拉取服务列表
predicates: # 路由断言,判断请求是否符合规范,符合则路由到目标服务
- Path=/user/** # 路径断言,判断路径是否以/user开头,符合则转发到目标地址
- id: item
uri: lb://item-service
predicates:
- Path=/items/**,/search/**
- id: user
uri: lb://user-service
predicates:
- Path=/users/**,/addresses/**
- id: trade
uri: lb://trade-service
predicates:
- Path=/orders/**
- id: pay
uri: lb://pay-service启动测试
启动UserApplication、GatewayApplication
启动网关,访问localhost:8080/items/page?pageNo=1&pageSize=1即被转发为locahost:8081/items/page?pageNo=1&pageSize=1
路由过滤器GatewayFilter
GatewayFilter是网关提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理:
官网:https://docs.spring.io/spring-cloud-gateway/reference/4.1-SNAPSHOT/spring-cloud-gateway.html ,现在已有近37种过滤配置
下面只做几个演示
案例-给所有进入xx服务的请求添加一个请求头
局部服务添加:
在网关的user-service中添加过滤器1
2
3
4
5
6
7
8gateway:
routes:
- id: user-service # 路由标识,必须唯一
uri: lb://user-service # 路由的目标地址
predicates: # 路由断言,判断请求是否符合规范
- Path=/user/** # 路径断言,判断路径是否以/user开头,符合则转发到目标地址
filters: # 过滤器
- AddRequestHeader=Truth,Facts are the only test of truth! # 添加请求头,key为Truth,value为Facts are the only test of truth!验证
在userservice的服务中获取请求头并打印中控制台来验证1
2
3
4
5
6
public User queryById( Long id,
String truth) {
System.out.println("Truth : "+truth);
return userService.queryById(id);
}当调用到该服务时可以看到
Truth : Facts are the only test of truth!被输出在控制台全局配置给所有微服务添加:
在于routers的平级位置下方添加default-filters1
2
3
4
5
6
7
8
9
10
11
12gateway:
routes:
- id: user # 路由标识,必须唯一
uri: lb://userservice # 路由的目标地址
predicates: # 路由断言,判断请求是否符合规范
- Path=/user/** # 路径断言,判断路径是否以/user开头,符合则转发到目标地址
- id: cart
uri: lb://cart-service
predicates:
- Path=/cart/**
default-filters: # 全局过滤器
- AddRequestHeader=Truth,Facts are the only test of truth!
全局过滤器 GlobalFilter
全局过滤器的作用是处理一切进入网关的请求和微服务响应,于GatewayFilter的作用一样,区别在于GatewayFilter通过配置定义,处理逻辑是固定的。而GlobalFilter的逻辑需要自己写代码实现
- 实现
实现方式为实现GlobalFilter接口1
2
3
4
5
6
7
8
9
10public interface GlobalFilter{
/**
* 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理
* @param exchange 请求上下文,里面可以获取Request、Response等信息
* @param chain 用来把请求委托给下一个过滤器
* @return {@code Mono<Void>}返回标示当前过滤器业务结束
*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}
案例-GlobalFilter实现登录验证拦截
情景模拟
- 通过一个模拟需求来演示如何实现:定义全局过滤器,拦截并判断用户身份
- 需求:定义全局过滤器,拦截请求,判断请求的参数是否满足以下条件:
- 判断是否需要拦截,部分请求路径不需要拦截
- 需要拦截就进行token解析验证
- 如果满足条件就放行,否则则拦截
1
2
3
4
5
6
7hm: #application,yml配置的不需要拦截的路径
auth:
excludePaths:
- /search/**
- /users/login
- /items/**
- /hi1
2
3
4
5
6
7//用于读取配置文件的类
public class AuthProperties {
private List<String> includePaths;
private List<String> excludePaths;
}
实现
在gateway网关模块中新建一个类AuthGlobalFilter- 1.实现GlobalFilter接口
- 2.添加@Order注解或实现Ordered接口
- 3.编写处理逻辑访问拦截范围中的业务如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63// @Order(-1)//值越小,优先级越高,也可以实现Ordered接口来实现优先级
public class AuthGlobalFilter implements GlobalFilter, Ordered {
// 注入jwt工具类
private final JwtTool jwtTool;
// 注入配置类
private final AuthProperties authProperties;
// 使用ant匹配器
private final AntPathMatcher antPathMatcher = new AntPathMatcher();
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//1. 获取request
ServerHttpRequest request = exchange.getRequest();
//2. 判断需不需要进行拦截
if(isExclude(request.getPath().toString())){
//请求的路径在排除路径中,无需拦截,放行
return chain.filter(exchange);
}
//3.获取请求头中的token
String token = null;
List<String> headers = request.getHeaders().get("authorization");
if(!CollUtil.isEmpty(headers)){
token = headers.get(0);
}
//4.校验并解析token
Long userID = null;
try{
userID = jwtTool.parseToken(token);//工具类中已经包含了对token的校验和解析逻辑,出现问题则抛出对应异常
}catch (Exception e){
// token无效,返回401
ServerHttpResponse response = exchange.getResponse();
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete();
}
//TODO 5.token有效则传递用户信息
System.out.println("userID"+userID);
//6.放行
return chain.filter(exchange);
}
//实现判断是否需要拦截逻辑
private boolean isExclude(String antPath) {
for(String pathPattern : authProperties.getExcludePaths()){
if(antPathMatcher.match(pathPattern,antPath)){
return true;
}
}
return false;
}
//设置优先级,越小优先级越高
public int getOrder() {
return 0;
}
}http://localhost:8080/carts/list即可验证,出现401错误
网关传递信息
上面的登录验证拦截中,网关已经可以完成登录校验并获取登录用户身份信息。但是当网关将请求转发到微服务时,微服务又该如何获取用户身份呢?
由于网关发送请求到微服务依然采用的是Http请求,因此我们可以将用户信息以请求头的方式传递到下游微服务。
然后微服务可以从请求头中获取登录用户信息。考虑到微服务内部可能很多地方都需要用到登录用户信息,因此我们可以利用SpringMVC的拦截器来实现登录用户信息获取,并存入ThreadLocal,方便后续使用。
改造网关过滤器,保存用户信息到请求头
在获取用户信息后保存到请求头,转发到下游微服务mutate()方法可以对下游请求做更改,.request表示对请求做处理,利用builder可以对请求中各种信息做修改
将上面6.3.1中的过滤逻辑代码的41~45行的代码修改如下1
2
3
4
5
6
7//保存用户信息到请求头中
String userInfo = userID.toString();
ServerWebExchange webExchange = exchange.mutate()
.request(b -> b.header("userinfo", userInfo))
.build();
//5.放行, 携带用户信息
return chain.filter(webExchange);拦截器获取用户
- 如所有微服务模块引用了一个common模块,那么只需要在common模块中添加拦截器即可
- 下面演示的common模块中已经有一个用于保存登录用户的ThreadLocal工具,其中已经提供了保存和获取用户的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public class UserContext {
private static final ThreadLocal<Long> tl = new ThreadLocal<>();
/**
* 保存当前登录用户信息到ThreadLocal
* @param userId 用户id
*/
public static void setUser(Long userId) {
tl.set(userId);
}
/**
* 获取当前登录用户信息
* @return 用户id
*/
public static Long getUser() {
return tl.get();
}
/**
* 移除当前登录用户信息
*/
public static void removeUser(){
tl.remove();
}
} - 实现拦截器并注册,但在网关这已经实现了拦截逻辑,所以这里只需要放行即可 注册拦截器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class UserInfoInterceptor implements HandlerInterceptor {
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//1.获取请求头
String userinfo = request.getHeader("userinfo");
if(StrUtil.isNotBlank(userinfo)){
//2.设置用户信息
UserContext.setUser(Long.valueOf(userinfo));
}
//3.放行
return true;
}
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex){
//清理用户
UserContext.removeUser();
}
}不过,需要注意的是,这个配置类默认是不会生效的,因为它所在的包是1
2
3
4
5
6
7
8
9
//WebMvcConfigurer属于WebMvc包下的,而网关是非阻塞基于响应式的,没有WebMvc包,因此需要判断
// 判断DispatcherServlet类是否存在
public class MvcConfig implements WebMvcConfigurer {
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new UserInfoInterceptor());
}
}com.hmall.common.config,与其它微服务的扫描包不一致,无法被扫描到,因此无法生效。
基于SpringBoot的自动装配原理,我们要将其添加到resources目录下的META-INF/spring.factories文件中:1
2
3
4org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.hmall.common.config.MyBatisConfig,\
com.hmall.common.config.JsonConfig,\
com.hmall.common.config.MvcConfig
执行顺序
路由过滤器,defaultFilter,全局过滤器的执行顺序:
- 1.order值越小,优先级越高
- 2.当order值一样时,顺序是defaultFilter最先,然后是局部路由过滤器,最后是全局过滤器
跨域问题处理
跨域:域名不一致就是跨域,主要包括:
域名不同:www.taobao.com 和www.taobao.org 和www.jd.com 和miaosha.jd.com
域名相同,端口不同:localhost:8080和localhost8081
跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
解决方案:CORS
1 | spring: |
路由断言工厂Route Predicate Factory
上面的配置文件中了解到predicates是路由断言,是判断规则。而配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件。
Spring提供了11种基本的Predicate工厂:
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-ld, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org, .anotherhost.org |
| Method | 请求方式必须是指定方式 | -Method=GET, POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/(segment),/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者-Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | -RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 |
Docker
镜像:Docker将应用程序及其所需的依赖,函数库,环境,配置文件等打包在一起,称为镜像。
容器:镜像中的应用程序运行后形成的进程就是容器,只是Docker会做容器做隔离,对外不可见。
docker架构
Docker是一个CS架构的程序,由两部分组成:
服务端(server):Docker守护进程,负责处理Docker指令,管理镜像,容器等
客户端(client):通过命令或RestAPI向Docker服务端发送指令。可以在本地或远程向服务端发送指令。
DockerHub
一个镜像托管的服务器,类似的还有阿里云镜像服务,统称为DockerRegistry
在CentOS上安装Docker
关于centos,可以看我往期linux的文章:
如果之前安装过旧版本的Docker,可以使用下面命令卸载:
1 | yum remove docker \ |
然后更新本地镜像源(阿里):
1 | 设置docker镜像源 |
更新yum,建立缓存
1 | sudo yum makecache fast |
最后,执行命令,安装Docker
1 | yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin |
docker-ce为社区免费版本。稍等片刻,docker即可安装成功。
启动docker
Docker应用需要用到各种端口,逐一去修改防火墙设置。非常麻烦,因此建议大家直接关闭防火墙!
1 | # 关闭 |
通过命令启动docker:
1 | systemctl start docker # 启动docker服务 |
1 | systemctl status docker # 查看docker服务状态 |
配置镜像加速
docker官方镜像仓库网速较差,我们需要设置国内镜像服务:
最新请参考阿里云的镜像加速文档:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
通过修改daemon配置文件/etc/docker/daemon.json来使用加速器
1 | sudo mkdir -p /etc/docker #创建文件夹 |
Docker基本操作
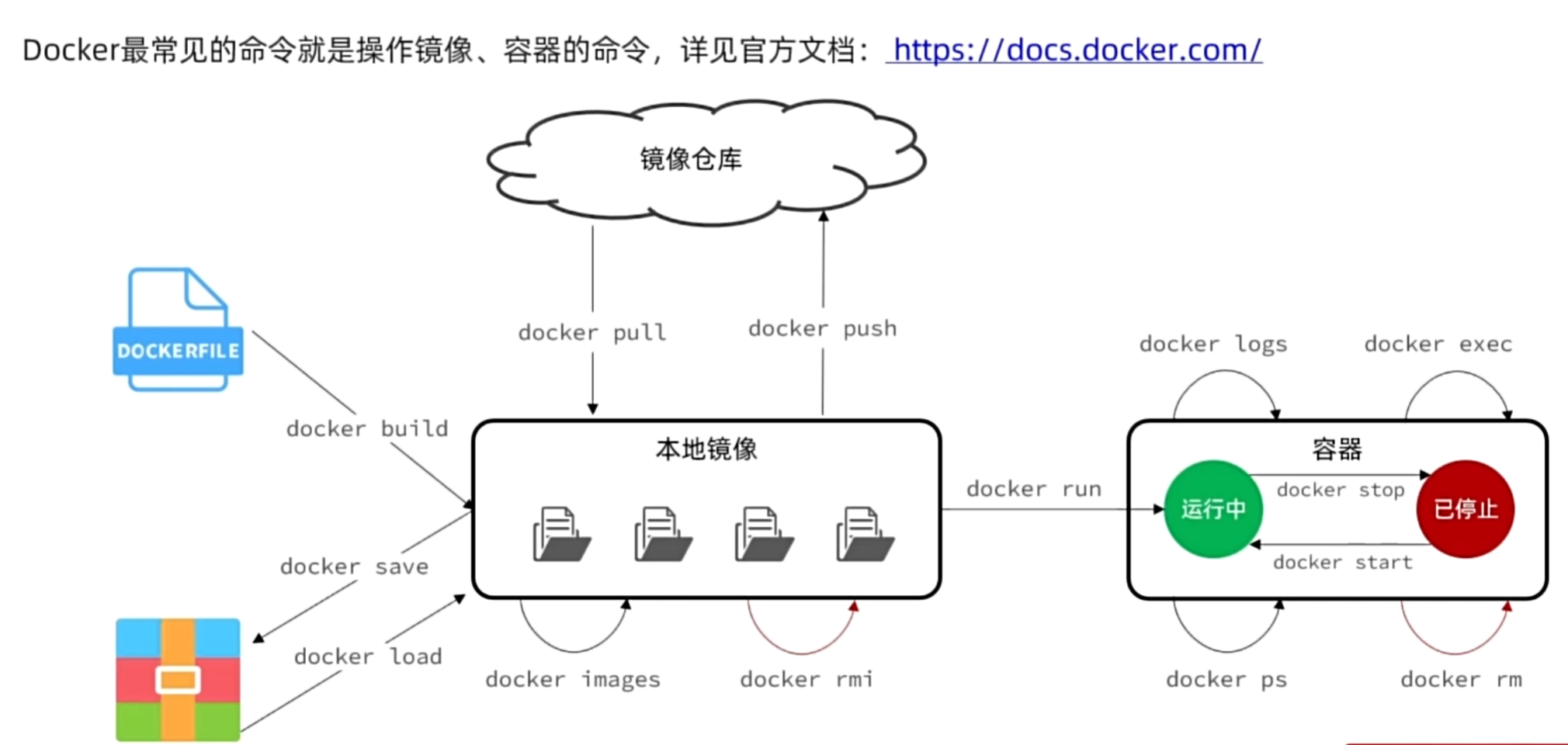
镜像操作
镜像名称一般由两部分组成:[repository]:[tag]。如mysql:5.7和mysql:5.6就是两个不同的镜像
如果不写tag,则默认拉取最新版本的,tag即为latest
| 操作 | 命令 |
|---|---|
| Dockerfile构建镜像到本地: | docker build |
| local(本地)查看镜像: | docker images |
| local(本地)删除镜像: | docker rmi 后面接镜像名 |
| 从Docker Registry镜像服务器拉取镜像到本地: | docker pull 后接[repository]:[tag] |
| 本地保存镜像为一个压缩包: | docker save 后接 -o 压缩包名 镜像名 |
| 加载压缩包为镜像: | docker load 后面接 压缩包名 |
| 更多命令请查看帮助文档: | docker --helper |
| 查看具体命令: | docker command --helpe |
例:拉取nignx的镜像:docker pull nginx
更多请前往:https://hub.docker.com/
嘘!更多有关docker镜像:
操作示例:1
2
3
4
5docker pull redis # 拉取最新的redis镜像
docker images # 查看本地镜像
docker save -o redis.tar redis:latest # 将redis:latest镜像保存为redis.tar压缩包
docker rmi redis:latest # 删除redis:latest镜像
docker load -i redis.tar # 将reids.tar压缩包加载为镜像
容器操作
镜像运行为容器:docker run
当不知道运行某个容器时,建议去dockerHub官网上查看:https://hub.docker.com/
| 容器常用操作 | 命令 |
|---|---|
| 运行到暂停 | docker pause |
| 暂停到运行 | docker unpasue |
| 运行到停止 | docker stop |
| 停止到运行 | docker start |
| 查看容器运行日志 | docker logs |
| 查看所有运行的容器及状态 | docker ps |
| 进入容器执行命令 | docker exec |
| 删除指定容器 | docker rm |
容器操作示例:拉取nginx镜像,创建一个nginx容器,运行nginx容器,进入nginx容器,修改html内容,添加”阿徐到此一游“ 运行一个名nginx的容器,取名为mn 去docker hub 查看Nginx的容器运行命令 运行完返回的一长串字符是容器id(CONTAINER ID) 进入容器: 可以看到界面左侧变成了: 切换路径: 替代原有的内容: 输入 输入 查看容器操作示例
docker pull nginx:拉取最新的nginx镜像docker run --name mn -p 80:80 -d nginx
命令解读:docker run: 创建并运行一个容器--name: 给容器取一个名字,这里叫mn-p:将宿主机端口与容器端口映射,冒号左侧是宿主端口,右侧是容器端口-d:后台运行容器nginx:镜像名称,列如nginx
如,我的虚拟机的ip为192.168.255.128,运行完后访问192.168.255.128:80即可看到nginx的运行界面docker logs mn:查看日志docker exec -it mn bash
命令解读:docker exec:进入容器内部,执行一个命令-it:给当前容器创建一个标准输入,输出终端,允许我们与容器交互mn:要进入的容器的名称,这里前面我们创建的nginx容器叫mnbash:进入容器后执行的命令,bash是一个linux终端交互命令容器id:/#的格式
输入pwd发现在根目录/,输入ls可以看到熟悉的home lib64 bin media root sys usr var等目录,这就是一个阉割的linux系统,我们需要找到nginx在哪个目录,访问https://hub.docker.com/_/nginx:官网可知静态资源应该放在/usr/share/nginx/html目录下。cd /usr/share/nginx/html,ls可看到50x.html和index.html1
2sed -i 's#Welcome to nginx#阿徐到此一游#g' index.html
sed -i 's#<head>#<head><meta charset="utf-8">#g' index.html
刷新网页即可看到改动。exit退出容器,停止容器:docker stop mndocker ps -a即可查看所有容器状态,包括已经停止的容器
数据卷(容器数据管理)
容器现在与数据十分耦合,导致不便于修改,数据不可复用,升级维护困难
数据卷(volume)是一个虚拟目录,指向宿主机文件系统中的某个目录
数据操作的基本语法为:docker volume [COMMAND]
docker volume命令是数据卷操作,根据命令后跟随的command来确定下一步操作:
- create 创建一个volume
- inspect 显示一个或多个volume的信息
- ls 列出所有的的volume
- prune 删除未使用的volume
- rm 删除一个或多个指定的volume
操作示例:创建一个数据卷,并查看数据卷在宿主机的目录位置 创建数据卷: 查看所有数据: 查看数据卷详细信息卷: 查看操作示例
docker volume create htmldocker volume lsdocker volume inspect html
挂载数据卷
我们在创建容器时,可以通过-v参数来挂载一个数据卷到某个容器目录
操作示例:创建一个nginx容器,修改容器内的html目录内的index.html内容 1.创建一个叫mn的nginx容器并运行它,同时挂载html数据卷到容器内的/usr/share/nginx/html目录上,并把nginx的80端口暴露在虚拟机80端口。 注:如果挂载时数据卷不存在,docker会自动创建该数据卷 2.查看数据卷html信息 3.进入数据卷所在位置,并修改html内容 现在我们可以直接在 注:如果用finashell在目录栏输入这个地址一直在加载的话,在finashell连接编辑中,把用户名改为root 右键index.html文件,用系统相关打开(如用vscode),用vscode直接编辑即可,保存刷新网页即可看到效果 查看操作示例挂载数据卷
docker run --name mn -p 80:80 -v html:/usr/share/nginx/html -d nginxdocker inspect html"Mountpoint": "/var/lib/docker/volumes/html/_data",,得知挂载点在这个目录里/var/lib/docker/volumes/html/_datacd /var/lib/docker/volumes/html/_datals发现里面存在了50x.html和index.html证明我们已经将容器的/usr/share/nginx/html目录挂载到了html数据卷的真实目录下/var/lib/docker/volumes/html/_data这个目录下对文件进行修改
我们也可以直接将宿主机的目录挂载到容器内的目录:-v [宿主机目录]:[容器内目录]
也可以将宿主机文件挂载到容器内文件:-v [宿主机文件]:[容器内文件]
Dockerfile自定义镜像
- Dockerfile的本质是一个文件,通过指令描述镜像的构建过程
- Dockerfile的第一行必须是FROM,从一个基础镜像来构建
- 基础镜像可以是基本操作系统,如Ubuntu。也可以是其他人制作好的镜像,例如:java:8-alpine
docker-network网段
1 | docker network create hm-net # 创建一个叫hm-net的网络 |
DockerCompose
DockerCompose的详细语法参考官网:https://docs.docker.com/compose/compose-file/
DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。
Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。
作用:帮助我们快速部署分布式应用,无需一个个微服务去构建镜像和部署。
下面为示例文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44version: '3'
services:
mysql:
image: mysql:5.7 # 指定镜像名
container_name: mysql # 指定容器名
ports:
- "3306:3306" # 映射端口
environment: # 设置环境变量
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: root
volumes: # 挂载数据卷
- "./mysql/data:/var/lib/mysql"
- "./mysql/conf:/etc/mysql/cnf.d"
- "./mysql/init:/docker-entrypoint-initdb.d"
networks: # 指定网络
- hm-net
hmall:
build:
context: . # 指定构建上下文,当前目录构建镜像
dockerfile: Dockerfile # 指定构建文件
container_name: hmall
ports:
- "8080:8080"
networks: # 指定网络
- hm-net
depends_on: # 依赖,可不写,写了会先创建依赖的容器
- mysql
nginx:
images: nginx
container_name: nginx
ports:
- "18080:18080"
- "18081:18081"
volumes:
- "./nginx/nginx.conf:/etc/nginx/nginx.conf"
- "./nginx/html:/usr/share/nginx/html"
depend_on:
- hmall
networks:
- hm-net
networks: # 创建网络
hm-net:
name: hmall
运行dockercompose命令:docker compose up -d创建并后台运行所有service容器
Docker镜像仓库
搭建私有镜像厂库
配置Docker信任地址
我们的私服采用的是http协议,默认不被Docker信任,所以需要做一个配置:
ip地址记得换成自己虚拟机的ip。1
2
3
4
5
6
7
8# 打开要修改的文件
vi /etc/docker/daemon.json
# 添加内容:
"insecure-registries":["http://192.168.255.128:8080"]
# 重加载
systemctl daemon-reload
# 重启docker
systemctl restart docker
带有图形化界面版本
1.创建一个docker镜像仓库存放的文件夹如:mkdir registry-ui(在哪个目录创建都差不多,这里是/tmp/)
2.进入该文件夹:cd registry-ui/
3.创建一个docker-compose文件:touch docker-compose.yml
4.将下面命令粘贴到文件内:
使用DockerCompose部署带有图象界面的DockerRegistry,命令如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15version: '3.0'
services:
registry:
image: registry
volumes:
- ./registry-data:/var/lib/registry
ui:
image: joxit/docker-registry-ui:static
ports:
- 8080:80
environment:
- REGISTRY_TITLE=阿杰学习私有仓库
- REGISTRY_URL=http://registry:5000
depends_on:
- registry
5.执行docker-compose up -d。之后查看日志docker-compose logs -f可以看到已经启动了,访问http://192.168.255.128:8080/即可看到我们部署的私有仓库
向私有仓库推送或拉取镜像
推送镜像到私有镜像服务前必须先tag,步骤如下:
本地有一个nginx:latest镜像,重新tag镜像,名称前缀为私有仓库的地址:
192.168.255.128:8080/docker tag nginx:latest 192.168.255.128:8080/nginx:1.0推送镜像
docker push 192.168.255.128:8080/nginx:1.0
刷新仓库界面,可以看到镜像上传到成功私有仓库拉取镜像
docker pull 192.168.255.128:8080/nginx:1.0
服务异步通讯-RabbitMQ
MQ,中文是消息队列,字面来看就是存放消息的队列。也就是事件驱动架构中的Broker
RabbitMQ是基于Erlang语言开发的开源消息通信中间件,官网地址:https://www.rabbitmq.com/
我们在Centos7虚拟机中使用Docker来安装。
安装
执行下面的命令来基于Docker来安装RabbitMQ(3.8版本):1
2
3
4
5
6
7
8
9
10
11docker run \
-e RABBITMQ_DEFAULT_USER=xnj \
-e RABBITMQ_DEFAULT_PASS=123321 \
-v mq-plugins:/plugins \
--name mq \
--hostname mq \
-p 15672:15672 \
-p 5672:5672 \
--network hm-net\
-d \
rabbitmq:3.8-management- 其中
--network hm-net是指定网络,需提前创建该网络,或直接不写,不写默认是bridge模式 - 其中
15672是控制台端口,5672是收发消息端口,
- 其中
访问mq控制台
访问:http://192.168.40.101:15672
首次访问需要登录,默认的用户名和密码在配置文件中已经指定了。
控制台中包含几个概念:- publisher:生产者,也就是发送消息的一方
- consumer:消费者,也就是消费消息的一方
- queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理
- exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。
- virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
发送消息
交换机
打开Exchanges选项卡,可以看到已经存在很多交换机
点击任意交换机,即可进入交换机详情页面。利用控制台中的publish message 发送一条消息- 点开
publish message,在Payload处填写消息体,点击publish message - 如:
hello everyone - 这里是由控制台模拟了生产者发送的消息。由于没有消费者存在,最终消息丢失了,这样说明交换机没有存储消息的能力。
交换机没有存储信息的能力, 只负责将信息转发到对应的队列中
- 点开
队列
打开Queues选项卡,新建一个队列:- 点开
Add a new queue - 在
Name处填写队列名称如:hello.queue1,点击Add queue添加队列 - 重复上面操作,再新建一个队列:
hello.queue2
现在如果再次发送消息依然会丢失,因为还需要将队列与交换机绑定。
- 点开
绑定
- 点击
Exchanges选项卡,点击amq.fanout交换机,进入交换机详情页 - 然后点击
Bindings菜单,在表单中填写要绑定的队列名称,在点击Bind进行绑定 - 依次重复步骤绑定步骤2创建的hello.queue1,hello.queue2队列
- 点击
发送消息
- 再次回到
exchange页面,找到刚刚绑定的amq.fanout,点击进入详情页,再次发送一条消息 - 回到
Queues页面,可以发现hello.queue中已经有一条消息了 - 点击队列名称,进入详情页,查看队列详情,这次我们点击
get message - 可以看到消息到达队列了。
- 再次回到
数据隔离
用户管理
点击Admin选项卡,首先会看到RabbitMQ控制台的用户管理界面:
这里的用户都是RabbitMQ的管理或运维人员。目前只有安装RabbitMQ时添加的itheima这个用户。仔细观察用户表格中的字段,如下:Name:xnj,也就是用户名Tags:administrator,说明itheima用户是超级管理员,拥有所有权限Can access virtual host:/,可以访问的virtual host,这里的/是默认的virtual host
搭建一套MQ集群,公司内的多个不同项目同时使用。这个时候为了避免互相干扰, 我们会利用virtual host的隔离特性,将不同项目隔离。一般会做两件事情:- 给每个项目创建独立的运维账号,将管理权限分离。
- 给每个项目创建不同的virtual host,将每个项目的数据隔离。
现在我们创建一个新用户如hmall,会发现此时hmall用户没有任何virtual host的访问权限:No access
虚拟主机
退出登录,切换为hmall用户登录,点击Admin选项卡,然后点击Virtual Hosts菜单,进入virtual host管理页
看到目前只有一个默认的virtual host,名字为 /。
给项目创建一个单独的virtual host,而不是使用默认的/。如/hmall
由于是登录hmall账户后创建的virtual host,因此回到users菜单,发现当前用户已经具备了对/hmall这个virtual host的访问权限了
此时,点击页面右上角的virtual host下拉菜单,切换virtual host为 /hmall
然后再次查看queues选项卡,会发现之前在xnj用户创建的helllo.queue1的队列已经看不到了
这就是基于virtual host 的隔离效果。
JAVA客户端-SpringAMQP
spring-amqp官方文档:https://spring.io/projects/spring-amqp/
快速入门(BasicQuenue)
创建一个mq-demo父工程,管理consumer和publisher两个子模块,后面以该项目来演示
- 利用控制台创建队列simple.queue
- 在publisher服务中,利用springAMQP直接向simple.queue发送消息
- 在consumer服务中,利用springAMQP编辑消费者,监听simple.queue队列
flowchart LR
publisher --> simple.queue --> consumer
项目引入
- 父工程
mq-demopom.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itcast.demo</groupId>
<artifactId>mq-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<modules>
<module>publisher</module>
<module>consumer</module>
</modules>
<packaging>pom</packaging>
<!-- springboot版本-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.12</version>
<relativePath/>
</parent>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!--Lombok依赖-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--AMQP依赖,包含RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<!--单元测试-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
</project> - 子工程
publisher和consumer仅artifactId不同,如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>mq-demo</artifactId>
<groupId>cn.itcast.demo</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<!-- <artifactId>consumer</artifactId> -->
<artifactId>publisher</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>
- 父工程
启动类
- Consumer模块
1
2
3
4
5
6
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
} - Publisher模块
1
2
3
4
5
6
public class PublisherApplication {
public static void main(String[] args) {
SpringApplication.run(PublisherApplication.class);
}
}
- Consumer模块
引入依赖并配置rabbitmq服务端信息
在两个modules中引入spring-boot-starter-amqp依赖,上面父工程已经引入,如下1
2
3
4
5<!--AMQP依赖,包含RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>在publisher和consumer中创建application.yml配置文件,如下
1
2
3
4
5
6
7spring:
rabbitmq:
host: 192.168.40.101 # 你的虚拟机IP
port: 5672 # 端口
virtual-host: /hmall # 虚拟主机
username: hmall # 用户名
password: 123321 # 密码其中虚拟主机和用户已经前面用户隔离中创建完成
发送消息
在publisher模块中,创建测试类,如下
spring已经提供了一个模板类RabbitTemplate,可以直接发送消息1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class PublisherApplicationTest {
private RabbitTemplate rabbitTemplate;
public void test_publisher(){
//1.队列名
String queueName = "simple.queue";
//2.消息
String message = "hello rabbitmq";
//3.发送消息
rabbitTemplate.convertAndSend(queueName,message);
}
}运行测试,打开控制台,可以看到消息已经发送到队列中
接收消息
在consumer模块中,创建监听类,如下
利用@RabbitListener来声明要监听的队列信息1
2
3
4
5
6
7
8
9
10
11
12
public class SpringRabbitListener {
// 利用RabbitListener来声明要监听的队列信息
// 将来一旦监听的队列中有了消息,就会推送给当前服务,调用当前方法,处理消息。
// 可以看到方法体中接收的就是消息体的内容
public void listenSimpleQueueMessage(String msg) throws InterruptedException {
log.info("消费者接收到消息:【{}】", msg);
}
}启动consumer服务,然后在publisher服务中运行测试代码,发送MQ消息。最终consumer收到消息,queue中消息被消费掉
rabbitmq官方写法比较繁琐,展开查看
consumer中创建测试类ConsumerTest1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public class ConsumerTest {
public static void main(String[] args) throws IOException, TimeoutException {
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.40.101");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("hmall");
factory.setPassword("123321");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.订阅消息
channel.basicConsume(queueName, true, new DefaultConsumer(channel){
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
// 5.处理消息
String message = new String(body);
System.out.println("接收到消息:【" + message + "】");
}
});
System.out.println("等待接收消息。。。。");
}
}
publisher中创建测试类PublisherTest1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public class PublisherTest {
public void testSendMessage() throws IOException, TimeoutException {
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.40.101");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("hmall");
factory.setPassword("123321");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.发送消息
String message = "hello, rabbitmq!";
channel.basicPublish("", queueName, null, message.getBytes());
System.out.println("发送消息成功:【" + message + "】");
// 5.关闭通道和连接
channel.close();
connection.close();
}
}
基本消息队列的消息发送流程
建立connection,建立channel,利用channel声明队列,使用channel向队列发送消息
debug运行PublisherTest,可以在rabbitMq看到,依次建立了连接,然后建立通道,有了通道后就可以向队列中发送消息,之后创建了一个simple.queue的队列,点开该队列,再点GetMessage(s),可以看到发送的消息内容:hello, rabbitmq!,并且可以注意到,发送了消息之后,发送者就已经关闭了通道和连接。
入门案例属于
BasicQueue基本消息队列,消息一旦消费就会从队列中删除,RabbitMQ没有消息回溯功能
任务模型(WorkQueues)
WorkQueues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息
flowchart LR
publisher --> queue --> consumer1
queue --> consumer2
工作队列可以提高消息处理速度,避免队列消息堆积
演示如下
在控制台中创建一个work.queue队列- publisher的测试类中定义方法,发送50条消息到work.queue
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class PublisherApplicationTest {
private RabbitTemplate rabbitTemplate;
public void test_workqueue(){
//1.队列名
String queueName = "work.queue";
//3.发送消息
for (int i = 0; i < 50; i++) {
//2.消息
String message = "hello rabbitmq_"+i;
rabbitTemplate.convertAndSend(queueName,message);
}
}
} - 在consumer的监听类中,定义两个消费者,分别监听work.queue队列,并打印消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class SpringRabbitListener {
// 利用RabbitListener来声明要监听的队列信息
// 将来一旦监听的队列中有了消息,就会推送给当前服务,调用当前方法,处理消息。
// 可以看到方法体中接收的就是消息体的内容
public void listenWorkQueueMessage1(String msg){
System.out.println("消费者1接收到消息:【" + msg + "】"+ LocalTime.now());
}
public void listenWorkQueueMessage2(String msg){
System.err.println("消费者2接收到消息:【" + msg + "】"+ LocalTime.now());
}
}
- publisher的测试类中定义方法,发送50条消息到work.queue
测试结果
重启consumer服务,启动publisher的测试方法,在consumer服务控制台可以看到,消费者1和消费者2一共消费了50条消息,并且消息是轮询的。
一个消费者打印的全是奇数索引消息,一个消费者打印的全是偶数索引消息,消费速度提高了。
即workqueue把消息分给了下面的两个消费者 但是 两个消费者不会拿到同一个消息 也就是消息不是给a就是给b 不是既给了a又给了b
即使现在给这两个方法加上不同的休眠时间如Thread.sleep(25),消息依然是平均分配,只是休眠时间短结束的快- 用一句话形容就是:速度快的早早休息了,速度慢的忙不过来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50消费者2接收到消息:【hello rabbitmq_0】17:30:09.010530200
消费者2接收到消息:【hello rabbitmq_2】17:30:09.011033600
消费者2接收到消息:【hello rabbitmq_4】17:30:09.011033600
消费者2接收到消息:【hello rabbitmq_6】17:30:09.011033600
消费者2接收到消息:【hello rabbitmq_8】17:30:09.011033600
消费者2接收到消息:【hello rabbitmq_10】17:30:09.011033600
消费者2接收到消息:【hello rabbitmq_12】17:30:09.011537400
消费者2接收到消息:【hello rabbitmq_14】17:30:09.011537400
消费者2接收到消息:【hello rabbitmq_16】17:30:09.011537400
消费者2接收到消息:【hello rabbitmq_18】17:30:09.012041700
消费者2接收到消息:【hello rabbitmq_20】17:30:09.012041700
消费者2接收到消息:【hello rabbitmq_22】17:30:09.012041700
消费者2接收到消息:【hello rabbitmq_24】17:30:09.012545700
消费者2接收到消息:【hello rabbitmq_26】17:30:09.012545700
消费者2接收到消息:【hello rabbitmq_28】17:30:09.012545700
消费者2接收到消息:【hello rabbitmq_30】17:30:09.013054300
消费者2接收到消息:【hello rabbitmq_32】17:30:09.013054300
消费者2接收到消息:【hello rabbitmq_34】17:30:09.013559100
消费者2接收到消息:【hello rabbitmq_36】17:30:09.013559100
消费者2接收到消息:【hello rabbitmq_38】17:30:09.013559100
消费者2接收到消息:【hello rabbitmq_40】17:30:09.014064100
消费者2接收到消息:【hello rabbitmq_42】17:30:09.014064100
消费者2接收到消息:【hello rabbitmq_44】17:30:09.014618100
消费者2接收到消息:【hello rabbitmq_46】17:30:09.014618100
消费者2接收到消息:【hello rabbitmq_48】17:30:09.014618100
消费者1接收到消息:【hello rabbitmq_1】17:30:09.010530200
消费者1接收到消息:【hello rabbitmq_3】17:30:09.011033600
消费者1接收到消息:【hello rabbitmq_5】17:30:09.011033600
消费者1接收到消息:【hello rabbitmq_7】17:30:09.011033600
消费者1接收到消息:【hello rabbitmq_9】17:30:09.011033600
消费者1接收到消息:【hello rabbitmq_11】17:30:09.011537400
消费者1接收到消息:【hello rabbitmq_13】17:30:09.011537400
消费者1接收到消息:【hello rabbitmq_15】17:30:09.011537400
消费者1接收到消息:【hello rabbitmq_17】17:30:09.012041700
消费者1接收到消息:【hello rabbitmq_19】17:30:09.012041700
消费者1接收到消息:【hello rabbitmq_21】17:30:09.012041700
消费者1接收到消息:【hello rabbitmq_23】17:30:09.012545700
消费者1接收到消息:【hello rabbitmq_25】17:30:09.012545700
消费者1接收到消息:【hello rabbitmq_27】17:30:09.012545700
消费者1接收到消息:【hello rabbitmq_29】17:30:09.012545700
消费者1接收到消息:【hello rabbitmq_31】17:30:09.013054300
消费者1接收到消息:【hello rabbitmq_33】17:30:09.013054300
消费者1接收到消息:【hello rabbitmq_35】17:30:09.013559100
消费者1接收到消息:【hello rabbitmq_37】17:30:09.013559100
消费者1接收到消息:【hello rabbitmq_39】17:30:09.013559100
消费者1接收到消息:【hello rabbitmq_41】17:30:09.013559100
消费者1接收到消息:【hello rabbitmq_43】17:30:09.014064100
消费者1接收到消息:【hello rabbitmq_45】17:30:09.014064100
消费者1接收到消息:【hello rabbitmq_47】17:30:09.014064100
消费者1接收到消息:【hello rabbitmq_49】17:30:09.014064100
- 用一句话形容就是:速度快的早早休息了,速度慢的忙不过来。
能者多劳
在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:1
2
3
4
5spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息让两消费者每次处理一条消息就休眠,消费者1休眠25毫秒
Thread.sleep(25),消费者2休眠50毫秒。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50消费者1接收到消息:【hello rabbitmq_0】17:27:02.115775600
消费者2接收到消息:【hello rabbitmq_1】17:27:02.115775600
消费者1接收到消息:【hello rabbitmq_2】17:27:02.143309
消费者2接收到消息:【hello rabbitmq_3】17:27:02.167719300
消费者1接收到消息:【hello rabbitmq_4】17:27:02.169238600
消费者1接收到消息:【hello rabbitmq_5】17:27:02.195012300
消费者2接收到消息:【hello rabbitmq_6】17:27:02.219174800
消费者1接收到消息:【hello rabbitmq_7】17:27:02.222468900
消费者1接收到消息:【hello rabbitmq_8】17:27:02.249097
消费者2接收到消息:【hello rabbitmq_9】17:27:02.271034400
消费者1接收到消息:【hello rabbitmq_10】17:27:02.275575100
消费者1接收到消息:【hello rabbitmq_11】17:27:02.301446900
消费者2接收到消息:【hello rabbitmq_12】17:27:02.323094
消费者1接收到消息:【hello rabbitmq_13】17:27:02.328148800
消费者1接收到消息:【hello rabbitmq_14】17:27:02.354941600
消费者2接收到消息:【hello rabbitmq_15】17:27:02.375228700
消费者1接收到消息:【hello rabbitmq_16】17:27:02.381401600
消费者1接收到消息:【hello rabbitmq_17】17:27:02.408785
消费者2接收到消息:【hello rabbitmq_18】17:27:02.427534900
消费者1接收到消息:【hello rabbitmq_19】17:27:02.435342800
消费者1接收到消息:【hello rabbitmq_20】17:27:02.461886800
消费者2接收到消息:【hello rabbitmq_21】17:27:02.479071900
消费者1接收到消息:【hello rabbitmq_22】17:27:02.488710900
消费者1接收到消息:【hello rabbitmq_23】17:27:02.515153700
消费者2接收到消息:【hello rabbitmq_24】17:27:02.530444
消费者1接收到消息:【hello rabbitmq_25】17:27:02.541684300
消费者1接收到消息:【hello rabbitmq_26】17:27:02.567682900
消费者2接收到消息:【hello rabbitmq_27】17:27:02.581791500
消费者1接收到消息:【hello rabbitmq_28】17:27:02.593976200
消费者1接收到消息:【hello rabbitmq_29】17:27:02.621164700
消费者2接收到消息:【hello rabbitmq_30】17:27:02.633468300
消费者1接收到消息:【hello rabbitmq_31】17:27:02.647640900
消费者1接收到消息:【hello rabbitmq_32】17:27:02.674414200
消费者2接收到消息:【hello rabbitmq_33】17:27:02.685406700
消费者1接收到消息:【hello rabbitmq_34】17:27:02.701433300
消费者1接收到消息:【hello rabbitmq_35】17:27:02.727603300
消费者2接收到消息:【hello rabbitmq_36】17:27:02.737242800
消费者1接收到消息:【hello rabbitmq_37】17:27:02.755201800
消费者1接收到消息:【hello rabbitmq_38】17:27:02.781181
消费者2接收到消息:【hello rabbitmq_39】17:27:02.789295400
消费者1接收到消息:【hello rabbitmq_40】17:27:02.807738
消费者1接收到消息:【hello rabbitmq_41】17:27:02.834852600
消费者2接收到消息:【hello rabbitmq_42】17:27:02.840952600
消费者1接收到消息:【hello rabbitmq_43】17:27:02.860792100
消费者1接收到消息:【hello rabbitmq_44】17:27:02.887461500
消费者2接收到消息:【hello rabbitmq_45】17:27:02.892848500
消费者1接收到消息:【hello rabbitmq_46】17:27:02.913989
消费者1接收到消息:【hello rabbitmq_47】17:27:02.940846300
消费者2接收到消息:【hello rabbitmq_48】17:27:02.944382600
消费者1接收到消息:【hello rabbitmq_49】17:27:02.967891
发布订阅(Publish、Subscribe)
发布和订阅模式与前面的区别是允许将同一消息发送给多个消费者,实现方式是加了exchange(交换机)
交换机能接收发送者发送的消息,将消息按规则路由到与之绑定的队列。
根据交换机的类型可以分为三种:
- Fanout Exchange: 广播
- Direct Exchange: 定向
- Topic Exchange: 话题
flowchart LR
publisher --> exchange --> queue1
exchange --> queue2 --> consumer3
queue1 --> consumer1
queue1 --> consumer2
Fanout Exchange(广播模式)
Fanout Exchange会将接收到的消息路由到每一个跟其绑定的queue,所以也叫广播模式
flowchart LR
publisher --> Fanout-exchange --> queue1 --> consumer1
Fanout-exchange --> queue2 --> consumer2
创建演示环境
在控制台创建队列fanout.queue1和fanout.queue2
创建一个交换机hmall.fanout,类型为fanout,并绑定上面2个队列创建演示环境
在publisher的测试类中发送消息,指定交换机的名称1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class PublisherApplicationTest {
private RabbitTemplate rabbitTemplate;
public void testFanoutQueue() {
// 交换机名称
String exchangeName = "hmall.fanout";
//消息
String message = "hello, everybody!";
//发送消息,第一个参数是交换机名称,第二个参数是路由键,第三个参数是消息
rabbitTemplate.convertAndSend(exchangeName,"", message);
}
}在consumer服务的监听类中添加两个消费者分别监听2个队列,fanout.queue1和fanout.queue2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class SpringRabbitListener {
// 监听队列1
public void listnFanoutQueue1(String msg){
log.info("消费者1接收到广播消息:【{}】", msg);
}
// 监听队列2
public void listnFanoutQueue2(String msg){
log.info("消费者2接收到广播消息:【{}】", msg);
}
}运行结果
启动consumer服务,运行publisher的测试方法,能看到一次发送,所有消费者都能接收到
Direct Exchange(定向模式)
Direct Exchange会将消息根据规则路由到指定的Queue,因此称为定向路由
- 每一个Queue都与Exchange设置一个
BindingKey - 发布者发送消息时,指定消息的
RoutingKey Exchange将消息路由到BindingKey与消息RoutingKey一致的队列
如下图:当routingKey=blue时,消息被路由到queue1,当routingKey=yellow时,消息被路由到queue2
flowchart LR
Publisher:routingKey --> DirectExchange --> Queue1:bindingKey:blue --> Consumer1
DirectExchange --> Queue2:bindingKey:yellow --> Consumer2
创建演示环境
- 在控制台创建队列
direct.queue1和direct.queue2 - 创建一个交换机
hmall.direct,类型为direct,并绑定上面2个队列 - 绑定队列时,指定
Routingkey,每次绑定一个Routingkey,可以绑定多次设置多个Routingkey- direct.queue1:Routingkey: red ,blue
- direct.queue2:Routingkey: red ,yellow
- 在控制台创建队列
在consummer服务的监听类中添加两个消费者分别监听2个队列,direct.queue1和direct.queue2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class SpringRabbitListener {
// 利用RabbitListener来声明要监听的队列信息
// 路由模式
public void listnDirectQueue1(String msg){
log.info("消费者1接收到消息:【{}】", msg);
}
// 路由模式
public void listnDirectQueue2(String msg){
log.info("消费者2接收到消息:【{}】", msg);
}
}在publisher服务的测试类中发送消息并指定发送的routerKey
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class PublisherApplicationTest {
private RabbitTemplate rabbitTemplate;
public void testDirectQueue(){
//1.交换机名
String exchangeName = "hmall.direct";
//2.消息
String message = "hello,everyone";
//3.路由键routingkey
String routingKey1 = "red";
String routingKey2 = "blue";
String routingKey3 = "yellow";
//3.发送消息,指定中间的参数routingKey,
rabbitTemplate.convertAndSend(exchangeName,routingKey1,message);
}
}- 当指定routingKey为red时,启动测试,发现两个队列都接收到了消息
- 当指定routingKey为blue时,启动测试,只有direct.queue1接收到了消息
- 当指定routingKey为yellow时,启动测试,只有direct.queue2接收到了消息
consumer控制台输出 消费者接收到direct.queue1的消息:【hello, blue!】
将路由键改为yellow 消费者接收到direct.queue2的消息:【hello, yellow!】
将路由键改为red :
消费者接收到direct.queue2的消息:【hello, red!】
消费者接收到direct.queue1的消息:【hello, red!】
TopicExchange
TopicExchange也是基于RoutingKey做消息路由,和DirectExchange类似,区别在于routingKey必须是多个单词列表,并且以.分隔
如:china.news 代表中国的新闻消息、china.weather 代表中国天气消息、japan.news日本新闻、japan.weather日本天气Queue与Exchange指定BindingKey时可以使用通配符:
#:代指0个或多个单词,如:china.#,#.news*:代指一个单词,如:china.*,*.news
flowchart LR
Publisher:routingKey --> TopicExchange --> Queue1:bindingKey:china.# --> Consumer1
TopicExchange --> Queue2:bindingKey:jpan.# --> Consumer2
TopicExchange --> Queue3:bindingKey:#.weather --> Consumer3
TopicExchange --> Queue4:bindingKey:#.news --> Consumer4
创建演示环境
- 在控制台创建队列
topic.queue1和topic.queue2 - 在控制台中,声明交换机
hmall.topic,将两个队列与其绑定- topic.queue1的bindingKey为
china.# - topic.queue2的bindingKey为
#.news
- topic.queue1的bindingKey为
- 在控制台创建队列
在consummer服务的监听类中添加两个消费者分别监听这两个个队列,topic.queue1,topic.queue2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class SpringRabbitListener {
// 利用RabbitListener来声明要监听的队列信息
public void listnTopicQueue1(String msg){
log.info("消费者1接收到消息:【{}】", msg);
}
public void listnTopicQueue2(String msg){
log.info("消费者2接收到消息:【{}】", msg);
}
}在publisher服务的测试类中发送消息并指定发送的routerKey
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class PublisherApplicationTest {
private RabbitTemplate rabbitTemplate;
public void testTopicQueue(){
//1.交换机名
String exchangeName = "hmall.topic";
//2.消息
String message = "今天,中国的农产值又创新高。。";
//3.路由键routingkey
String routingKey1 = "china.news";
//3.发送消息,指定中间的参数routingKey
rabbitTemplate.convertAndSend(exchangeName,routingKey1,message);
}
}- 当指定routingKey为china.news时,启动测试,发现两个队列都接收到了消息
- 当指定routingKey为china.weather时,启动测试,只有topic.queue1接收到了消息
声明队列交换机
说明
在上面,我们创建交换机和队列,以及绑定交换机,设置bindingKey都是在控制台,下面介绍使用代码的方式- 队列:SpringAMQP提供了一个
Queue类,用来创建队列1
2
3
4
5// 声明队列1
public Queue fanoutQueue1(){
return new Queue("fanout.queue1");
} - 交换机:SpringAMQP还提供了一个
Exchange接口,来表示所有不同类型的交换机classDiagram class `TopicExchange` class `CustomExchange` class `FanoutExchange` class `DirectExchange` class `HeaderExchange` class `AbstractExchange` class `Exchange` `TopicExchange` --> `AbstractExchange` `CustomExchange` --> `AbstractExchange` `FanoutExchange` --> `AbstractExchange` `DirectExchange` --> `AbstractExchange` `HeaderExchange` --> `AbstractExchange` `AbstractExchange` .. `Exchange`
1
2
3
4
5//声明广播交换机
public FanoutExchange fanoutExchange(){
return new FanoutExchange("hmall.fanout");
} - 绑定:使用工厂类
BindingBuilder来创建Binding对象:可以自己创建队列和交换机,不过SpringAMQP还提供了ExchangeBuilder来简化这个过程1
2
3
4
5//绑定广播交换机和声明队列
public Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class FanoutConfig2 {
//声明FanoutExchange交换机
public FanoutExchange fanoutExchange() {
return ExchangeBuilder
.fanoutExchange("fanout_exchange").build();
}
//声明队列
public Queue fanoutQueue1() {
return QueueBuilder
.durable("fanout.queue1").build();
}
//绑定队列和交换机
public Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
}
- 队列:SpringAMQP提供了一个
演示
在consumer服务中的config包中添加一个配置类,用来声明交换机,队列,绑定队列和交换机
注意:如果是有进行前面的演示操作,记得先在控制台把hmall.fanout,fanout.queue1和fanout.queue2删除,否则会报错1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
public class FanoutConfig {
//声明广播交换机
public FanoutExchange fanoutExchange(){
return new FanoutExchange("hmall.fanout");
}
// 声明队列1
public Queue fanoutQueue1(){
return new Queue("fanout.queue1");
}
//绑定广播交换机和声明队列1
public Binding fanoutQueue1Binding(Queue fanoutQueue1, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
// 声明队列2
public Queue fanoutQueue2(){
return new Queue("fanout.queue2");
}
//绑定广播交换机和声明队列2
public Binding fanoutQueue2Binding(Queue fanoutQueue2, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
//如果是其他类型交换机,后面还可以跟参数.with("routingKey"),来声明绑定的routingKey
//但这种一个方法只能声明一个routingKey,声明多个routingKey就得定义多个方法,会变得很麻烦
}
}监听器类如下,用于监听两个队列,fanout.queue1,fanout.queue2,用于测试时接收消息
1
2
3
4
5
6
7
8
9
10
11
12
13
public class SpringRabbitListener {
// 广播模式
public void listnFanoutExchange1(String msg){
log.info("消费者1接收到广播消息:【{}】", msg);
}
public void listnFanoutExchange2(String msg){
log.info("消费者2接收到广播消息:【{}】", msg);
}
}测试
重启consumer服务,在publisher服务中运行测试方法向hmall.fanout发送消息1
2
3
4
5
6
7
8
9
public void testFanoutQueue(){
//1.交换机名
String exchangeName = "hmall.fanout";
//2.消息
String message = "hello,mq";
//3.发送消息,中间的参数是路由键,fanout类型交换机不需要设置路由键
rabbitTemplate.convertAndSend(exchangeName,"",message);
}观察consumer服务控制台输出的日志,发现两个队列都接收到了消息
前往mq控制台,发现创建了hmall.fanout交换机,并且创建了fanout.queue1和fanout.queue2两个队列,并且绑定了交换机
基于注解的声明队列交换机的方式
基于@Bean的方式声明队列和交换机比较麻烦,Spring还提供了基于注解方式来声明。
声明Direct模式的交换机和队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public class SpringRabbitListener {
// 利用RabbitListener来声明要监听的队列信息
// 路由模式
//声明direct队列监听,并绑定交换机和指定路由键
public void listnDirectQueue1(String msg){
log.info("消费者1接收到消息:【{}】", msg);
}
public void listnDirectQueue2(String msg){
log.info("消费者2接收到消息:【{}】", msg);
}
}声明Topic模式的交换机和队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public class SpringRabbitListener {
// 利用RabbitListener来声明要监听的队列信息
// 通配符模式
// 主题模式
public void listnTopicQueue1(String msg){
log.info("消费者1接收到消息:【{}】", msg);
}
public void listnTopicQueue2(String msg){
log.info("消费者2接收到消息:【{}】", msg);
}
}
SpringAMQP—消息转换器
前面我们发送的方法中,消息的类型是Object,也就是说我们可以发送任意对象类型的消息,SpringAMQP会帮我们序列化为字节后发送。
测试默认消息转换器
在控制台创建一个队列object.queue
在publisher中发送消息以测试1
2
3
4
5
6
7
8
9
10
11
12
public void testSerialQueue(){
//1.队列名
String queueName = "object.queue";
//2.消息
//准备消息
Map<String, Object> msg = new HashMap<>();
msg.put("name", "张三");
msg.put("age", 20);
//3.发送消息
rabbitTemplate.convertAndSend(queueName,msg);
}在mq控制台可以看到消息是乱码的,这是因为我们没有定义消息转换器,默认使用的是SimpleMessageConverter,基于IDK的ObjectOutputStream完成序列化。
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。引入json依赖
在publisher和consumer两个服务中都引入依赖1
2
3
4
5
6<!--用于将Java对象与JSON数据进行相互转换-->
<!--提供了ObjectMapper类,用于序列化和反序列化JSON数据。-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>配置消息转换器
在publisher和consumer两个服务创建配置类并添加如下的bean
或者直接中启动类中添加Bean即可1
2
3
4
public MessageConverter messageConverter() {
return new Jackson2JsonMessageConverter();
}测试结果
注意:publisher是用Map发送,那么消费者也一定要用Map接收
启动consumer服务并在publisher中发送消息以测试
consumer控制台输出:消费者接收到object.queue的消息:【{name=张三, age=20}】




